Research Overview
Our lab focuses on enabling robots to interact robustly with users in unconstrained and dynamic environments. We draw upon insights from artificial intelligence, human-robot interaction, procedural content generation, and quality diversity optimization to make fundamental advances in both developing interactive robots that assist users in complex, real-world tasks, as well as in generating complex, diverse, and realistic scenarios that effectively test the developed systems to enhance their robustness.
Research Contribution #1: Robot Assistance in Human Environments ¶
In order for robots to be effective assistants in human environments, they need to be able to adapt to the human user, based on the user’s physical characteristics, their individualized preferences, and their priorities on how to execute the task. For example, a robot that helps a post-stroke patient with hair combing should recognize and follow the user’s hair style. A manufacturing robot that supports human workers in assembly manufacturing should anticipate which tool a worker is going to need next. While much prior work has focused on learning from demonstration, in many such tasks human demonstrations are tedious, time-consuming, or impractical.
We have designed algorithms that efficiently infer the the user’s physical and mental states. This is made possible with very little data by using compact representations of these states and prior knowledge in the form of dominant user preferences and signal temporal logic. Our models have enabled general-purpose robotic arms to proactively assist users in a variety of tasks, such as IKEA assembly, hair combing, and meal preparation.
A Metric for Characterizing the Arm Nonuse Workspace in Poststroke Individuals Using a Robot Arm
N. Dennler, A. Cain, E. D. Guzmann, C. Chiu, C. J. Winstein, S. Nikolaidis, M. J. Matarić
Science Robotics, 2023
Abstract
An overreliance on the less-affected limb for functional tasks at the expense of the paretic limb and in spite of recovered capacity is an often-observed phenomenon in survivors of hemispheric stroke. The difference between capacity for use and actual spontaneous use is referred to as arm nonuse. Obtaining an ecologically valid evaluation of arm nonuse is challenging because it requires the observation of spontaneous arm choice for different tasks, which can easily be influenced by instructions, presumed expectations, and awareness that one is being tested. To better quantify arm nonuse, we developed the bimanual arm reaching test with a robot (BARTR) for quantitatively assessing arm nonuse in chronic stroke survivors. The BARTR is an instrument that uses a robot arm as a means of remote and unbiased data collection of nuanced spatial data for clinical evaluations of arm nonuse. This approach shows promise for determining the efficacy of interventions designed to reduce paretic arm nonuse and enhance functional recovery after stroke. We show that the BARTR satisfies the criteria of an appropriate metric for neurorehabilitative contexts: It is valid, reliable, and simple to use. Interacting with a robot can quantify otherwise hard-to-measure clinical metrics.
Transfer learning of human preferences for proactive robot assistance in assembly tasks
H. Nemlekar, A. Guan, N. Dhanaraj, S. Gupta, and S. Nikolaidis
Proceedings of the ACM/IEEE International Conference on Human-Robot Interaction (HRI), March 2023
Best Systems Paper Award Finalist
Abstract
We focus on enabling robots to proactively assist humans in assembly tasks by adapting to their preferred sequence of actions. Much work on robot adaptation requires human demonstrations of the task. However, human demonstrations of real-world assemblies can be tedious and time-consuming. Thus, we propose learning human preferences from demonstrations in a shorter, canonical task to predict user actions in the actual assembly task. The proposed system uses the preference model learned from the canonical task as a prior and updates the model through interaction when predictions are inaccurate. We evaluate the proposed system in simulated assembly tasks and in a real-world human-robot assembly study and we show that both transferring the preference model from the canonical task, as well as updating the model online, contribute to improved accuracy in human action prediction. This enables the robot to proactively assist users, significantly reduce their idle time, and improve their experience working with the robot, compared to a reactive robot.
Learning performance graphs from demonstrations via task-based evaluations
A. Puranic, J. Deshmukh, and S. Nikolaidis
Robotics and Automation Letters (RA-L), 2022
Abstract
In the paradigm of robot learning-from-demonstra tions (LfD), understanding and evaluating the demonstrated behaviors plays a critical role in extracting control policies for robots. Without this knowledge, a robot may infer incorrect reward functions that lead to undesirable or unsafe control policies. Prior work has used temporal logic specifications, manually ranked by human experts based on their importance, to learn reward functions from imperfect/suboptimal demonstrations. To overcome reliance on expert rankings, we propose a novel algorithm that learns from demonstrations, a partial ordering of provided specifications in the form of a performance graph. Through various experiments, including simulation of industrial mobile robots, we show that extracting reward functions with the learned graph results in robot policies similar to those generated with the manually specified orderings. We also show in a user study that the learned orderings match the orderings or rankings by participants for demonstrations in a simulated driving domain. These results show that we can accurately evaluate demonstrations with respect to provided task specifications from a small set of imperfect data with minimal expert input.
Towards transferring human preferences from canonical to actual assembly tasks
H. Nemlekar, R. Guan, G. Luo, S. Gupta, S. Nikolaidis
Proceedings of the IEEE International Conference on Robot & Human Interactive Communication (RO-MAN), 2022
Abstract
To assist human users according to their individual preference in assembly tasks, robots typically require user demonstrations in the given task. However, providing demonstrations in actual assembly tasks can be tedious and time-consuming. Our thesis is that we can learn user preferences in assembly tasks from demonstrations in a representative canonical task. Inspired by previous work in economy of human movement, we propose to represent user preferences as a linear function of abstract task-agnostic features, such as movement and physical and mental effort required by the user. For each user, we learn their preference from demonstrations in a canonical task and use the learned preference to anticipate their actions in the actual assembly task without any user demonstrations in the actual task. We evaluate our proposed method in a model-airplane assembly study and show that preferences can be effectively transferred from canonical to actual assembly tasks, enabling robots to anticipate user actions.
Design and Evaluation of a Hair Combing System Using a General-Purpose Robotic Arm
N. Dennler, E. Shin, M. Matarić, S. Nikolaidis
2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2021
Abstract
This work introduces an approach for automatic hair combing by a lightweight robot. For people living with limited mobility, dexterity, or chronic fatigue, combing hair is often a difficult task that negatively impacts personal routines. We propose a modular system for enabling general robot manipulators to assist with a hair-combing task. The system consists of three main components. The first component is the segmentation module, which segments the location of hair in space. The second component is the path planning module that proposes automatically-generated paths through hair based on user input. The final component creates a trajectory for the robot to execute. We quantitatively evaluate the effectiveness of the paths planned by the system with 48 users and qualitatively evaluate the system with 30 users watching videos of the robot performing a hair-combing task in the physical world. The system is shown to effectively comb different hairstyles.
Two-Stage Clustering of Human Preferences for Action Prediction in Assembly Tasks
H. Nemlekar, J. Modi, S. Gupta, S. Nikolaidis
2021 IEEE International Conference on Robotics and Automation (ICRA), May 2021
Abstract
To effectively assist human workers in assembly tasks a robot must proactively offer support by inferring their preferences in sequencing the task actions. Previous work has focused on learning the dominant preferences of human workers for simple tasks largely based on their intended goal. However, people may have preferences at different resolutions: they may share the same high-level preference for the order of the sub-tasks but differ in the sequence of individual actions. We propose a two-stage approach for learning and inferring the preferences of human operators based on the sequence of sub-tasks and actions. We conduct an IKEA assembly study and demonstrate how our approach is able to learn the dominant preferences in a complex task. We show that our approach improves the prediction of human actions through cross-validation. Lastly, we show that our two-stage approach improves the efficiency of task execution in an online experiment, and demonstrate its applicability in a real-world robot-assisted IKEA assembly.
Personalizing User Engagement Dynamics in a Non-Verbal Communication Game for Cerebral Palsy
N. Dennler, C. Yunis, J. Realmuto, T. Sanger, S. Nikolaidis, M. Matarić
2021 30th IEEE International Conference on Robot Human Interactive Communication (RO-MAN), 2021
Abstract
Children and adults with cerebral palsy (CP) can have involuntary upper limb movements as a consequence of the symptoms that characterize their motor disability, leading to difficulties in communicating with caretakers and peers. We describe how a socially assistive robot may help individuals with CP to practice non-verbal communicative gestures using an active orthosis in a one-on-one number-guessing game. We performed a user study and data collection with participants with CP; we found that participants preferred an embodied robot over a screen-based agent, and we used the participant data to train personalized models of participant engagement dynamics that can be used to select personalized robot actions. Our work highlights the benefit of personalized models in the engagement of users with CP with a socially assistive robot and offers design insights for future work in this area.
Learning from Demonstrations using Signal Temporal Logic
A. Puranic, J. Deshmukh, S. Nikolaidis
Conference on Robot Learning, November 2020
Abstract
We present a model-based reinforcement learning framework for robot locomotion that achieves walking based on only 4.5 minutes of data collected on a quadruped robot. To accurately model the robot’s dynamics over a long horizon, we introduce a loss function that tracks the model’s prediction over multiple timesteps. We adapt model predictive control to account for planning latency, which allows the learned model to be used for real time control. Additionally, to ensure safe exploration during model learning, we embed prior knowledge of leg trajectories into the action space. The resulting system achieves fast and robust locomotion. Unlike model-free methods, which optimize for a particular task, our planner can use the same learned dynamics for various tasks, simply by changing the reward function.1 To the best of our knowledge, our approach is more than an order of magnitude more sample efficient than current model-free methods.
Research Contribution #2: Automatic Scenario Generation ¶
For HRI systems to be widely accepted and used, they need to perform robustly in human environments. Traditionally, human-robot interaction (HRI) algorithms are tested with human subject experiments. While these experiments are fundamental in exploring and evaluating human-robot interactions and can lead to exciting and unpredictable behaviors, they are often limited in the number of environments and human actions that they can cover. Exhaustive search of human actions and environments is also computationally prohibitive. This highlights a critical need for automatically generating HRI scenarios; failure to do so can lead to infrequent scenarios that are undiscovered during testing but occur in large-scale real-world deployments, resulting in potentially costly failures.
Our goal is to find scenarios that are diverse, complex and realistic. Our insight is to formulate this as a quality diversity problem, where the goal is to generate scenarios that are diverse with respect to specific measures of interest. Drawing upon insights from procedural content generation, we integrate state-of-the-art quality diversity algorithms with generative models trained with human examples to generate diverse scenarios in simulation that are also complex and realistic.
Surrogate Assisted Generation of Human-Robot Interaction Scenarios
V. Bhatt, H. Nemlekar, M. C. Fontaine, B. Tjanaka, H. Zhang, Y. Hsu, and S. Nikolaidis
Conference on Robot Learning, November 2023
CoRL 2023 Oral
Abstract
As human-robot interaction (HRI) systems advance, so does the difficulty of evaluating and understanding the strengths and limitations of these systems in different environments and with different users. To this end, previous methods have algorithmically generated diverse scenarios that reveal system failures in a shared control teleoperation task. However, these methods require directly evaluating generated scenarios by simulating robot policies and human actions. The computational cost of these evaluations limits their applicability in more complex domains. Thus, we propose augmenting scenario generation systems with surrogate models that predict both human and robot behaviors. In the shared control teleoperation domain and a more complex shared workspace collaboration task, we show that surrogate assisted scenario generation efficiently synthesizes diverse datasets of challenging scenarios. We demonstrate that these failures are reproducible in real-world interactions.
Deep Surrogate Assisted Generation of Environments
V. Bhatt*, B. Tjanaka*, M. C. Fontaine*, S. Nikolaidis
Neural Information Processing Systems (NeurIPS), November 2022
Evaluating Human-Robot Interaction Algorithms in Shared Autonomy via Quality Diversity Scenario Generation
M. C. Fontaine, S. Nikolaidis
ACM Transactions on Human-Robot Interaction, 2022
Abstract
The growth of scale and complexity of interactions between humans and robots highlights the need for new computational methods to automatically evaluate novel algorithms and applications. Exploring diverse scenarios of humans and robots interacting in simulation can improve understanding of the robotic system and avoid potentially costly failures in real-world settings. We formulate this problem as a quality diversity (QD) problem, where the goal is to discover diverse failure scenarios by simultaneously exploring both environments and human actions. We focus on the shared autonomy domain, where the robot attempts to infer the goal of a human operator, and adopt the QD algorithms CMA-ME and MAP-Elites to generate scenarios for two published algorithms in this domain: shared autonomy via hindsight optimization and linear policy blending. Some of the generated scenarios confirm previous theoretical findings, while others are surprising and bring about a new understanding of state-of-the-art implementations. Our experiments show that the QD algorithms CMA-ME and MAP-Elites outperform Monte-Carlo simulation and optimization based methods in effectively searching the scenario space, highlighting their promise for automatic evaluation of algorithms in human-robot interaction.
On the Importance of Environments in Human-Robot Coordination
M. C. Fontaine*, Y. Hsu*, Y. Zhang*, B. Tjanaka, S. Nikolaidis
Robotics: Science and Systems, July 2021
Abstract
When studying robots collaborating with humans, much of the focus has been on robot policies that coordinate fluently with human teammates in collaborative tasks. However, less emphasis has been placed on the effect of the environment on coordination behaviors. To thoroughly explore environments that result in diverse behaviors, we propose a framework for procedural generation of environments that are (1) stylistically similar to human-authored environments, (2) guaranteed to be solvable by the human-robot team, and (3) diverse with respect to coordination measures. We analyze the procedurally generated environments in the Overcooked benchmark domain via simulation and an online user study. Results show that the environments result in qualitatively different emerging behaviors and statistically significant differences in collaborative fluency metrics, even when the robot runs the same planning algorithm.
A Quality Diversity Approach to Automatically Generating Human-Robot Interaction Scenarios in Shared Autonomy
M. C. Fontaine, S. Nikolaidis
Robotics: Science and Systems, July 2021
Abstract
The growth of scale and complexity of interactions between humans and robots highlights the need for new computational methods to automatically evaluate novel algorithms and applications. Exploring diverse scenarios of humans and robots interacting in simulation can improve understanding of the robotic system and avoid potentially costly failures in real-world settings. We formulate this problem as a quality diversity (QD) problem, where the goal is to discover diverse failure scenarios by simultaneously exploring both environments and human actions. We focus on the shared autonomy domain, where the robot attempts to infer the goal of a human operator, and adopt the QD algorithm MAP-Elites to generate scenarios for two published algorithms in this domain: shared autonomy via hindsight optimization and linear policy blending. Some of the generated scenarios confirm previous theoretical findings, while others are surprising and bring about a new understanding of state-of-the-art implementations. Our experiments show that MAP-Elites outperforms Monte-Carlo simulation and optimization based methods in effectively searching the scenario space, highlighting its promise for automatic evaluation of algorithms in human-robot interaction.
Illuminating Mario Scenes in the Latent Space of a Generative Adversarial Network
M. C. Fontaine, R. Liu, A. Khalifa, J. Modi, J. Togelius, A. Hoover, S. Nikolaidis
AAAI Conference on Artificial Intelligence, February 2021
Abstract
Generative adversarial networks (GANs) are quickly becoming a ubiquitous approach to procedurally generating video game levels. While GAN generated levels are stylistically similar to human-authored examples, human designers often want to explore the generative design space of GANs to extract interesting levels. However, human designers find latent vectors opaque and would rather explore along dimensions the designer specifies, such as number of enemies or obstacles. We propose using state-of-the-art quality diversity algorithms designed to optimize continuous spaces, i.e. MAP-Elites with a directional variation operator and Covariance Matrix Adaptation MAP-Elites, to efficiently explore the latent space of a GAN to extract levels that vary across a set of specified gameplay measures. In the benchmark domain of Super Mario Bros, we demonstrate how designers may specify gameplay measures to our system and extract high-quality (playable) levels with a diverse range of level mechanics, while still maintaining stylistic similarity to human authored examples. An online user study shows how the different mechanics of the automatically generated levels affect subjective ratings of their perceived difficulty and appearance.
Video Game Level Repair via Mixed Integer Linear Programming
H. Zhang*, M. C. Fontaine*, A. Hoover, J. Togelius, B. Dilkina, S. Nikolaidis
AAAI Conference on Artificial Intelligence and Interactive Digital Entertainment, October 2020
Abstract
Recent advancements in procedural content generation via machine learning enable the generation of video-game levels that are aesthetically similar to human-authored examples. However, the generated levels are often unplayable without additional editing. We propose a “generate-then-repair” framework for automatic generation of playable levels adhering to specific styles. The framework constructs levels using a generative adversarial network (GAN) trained with human-authored examples and repairs them using a mixed-integer linear program (MIP) with playability constraints. A key component of the framework is computing minimum cost edits between the GAN generated level and the solution of the MIP solver, which we cast as a minimum cost network flow problem. Results show that the proposed framework generates a diverse range of playable levels, that capture the spatial relationships between objects exhibited in the human-authored levels.
Research Contribution #3: Quality Diversity Optimization ¶
Searching the vast space of HRI scenarios requires algorithms that explore efficiently very high-dimensional continuous domains. We focus on a class of stochastic optimization algorithms, named quality diversity (QD) algorithms, which search for a range of high-quality solutions that are diverse with respect to measures of interest. Current state-of-the-art QD algorithms find new solutions by perturbing existing high-quality solutions with Gaussian noise, or through variation operators that exploit local correlations. However, these algorithms face difficulties when the low-dimensional measure space that we wish to cover is distorted, e.g., when uniformly sampling the space of scenarios results in scenarios that are nearly identical with respect to the measures that we wish to have diversity for.
Our insight is that we can leverage the adaptation properties of the CMA-ES derivative-free optimization algorithm to dynamically adapt the step size of our search based on how our archive of solutions is changing. Using this insight we propose a new class of algorithms that bring together the self-adaptation of CMA-ES with the archiving properties of MAP-Elites to approximate a natural gradient of the quality diversity objective. Our algorithms can also leverage the gradient information of the objective and measure functions to achieve significant gains in performance.
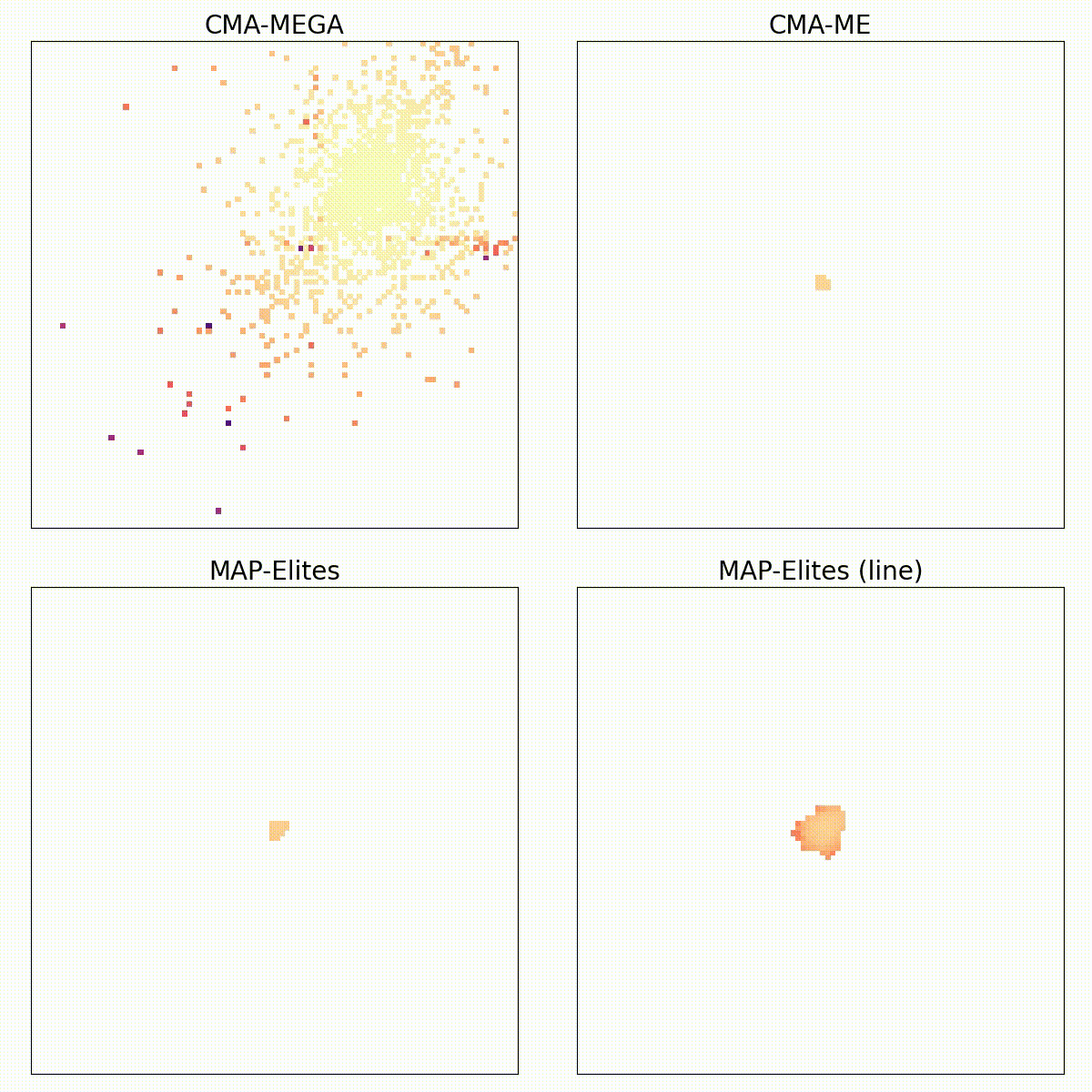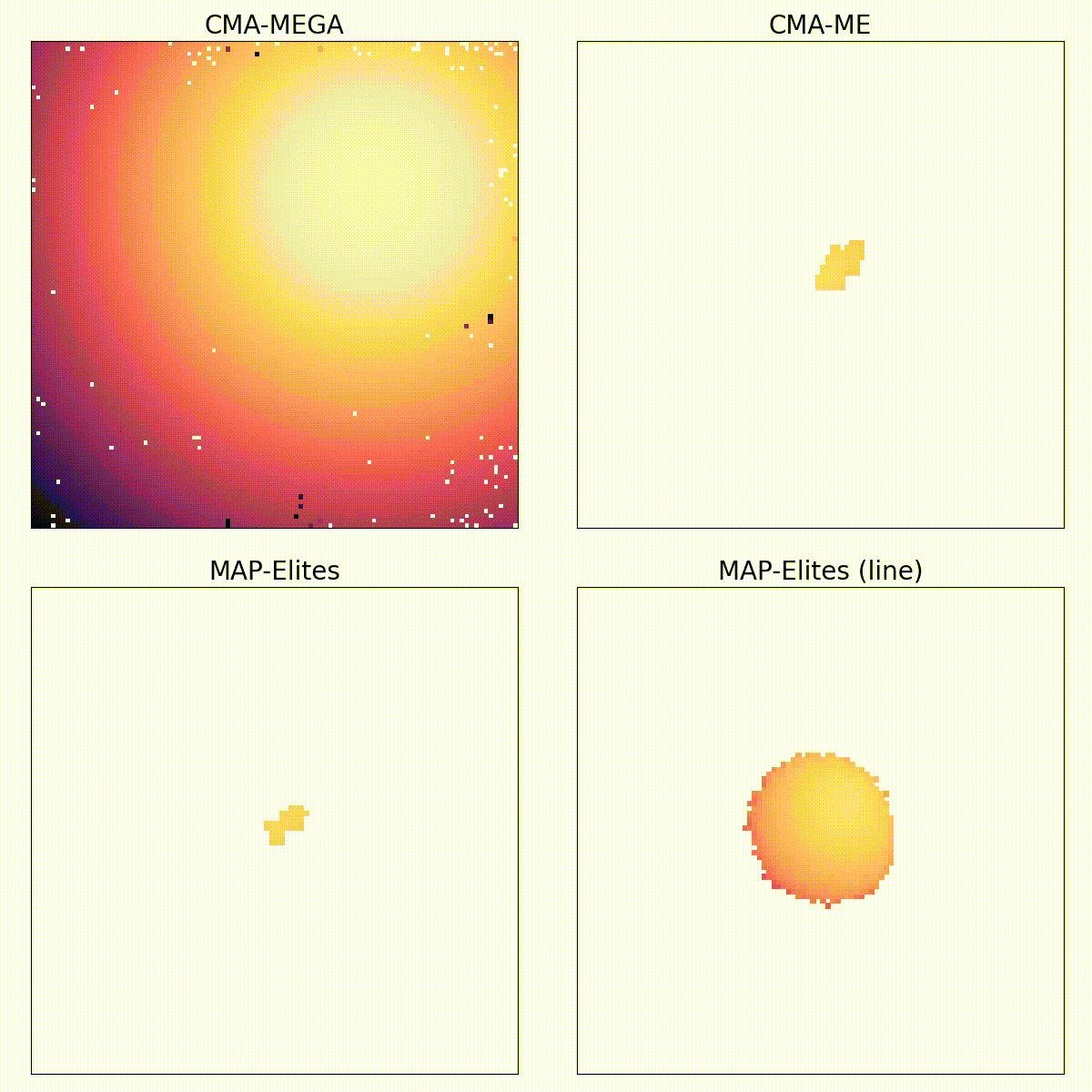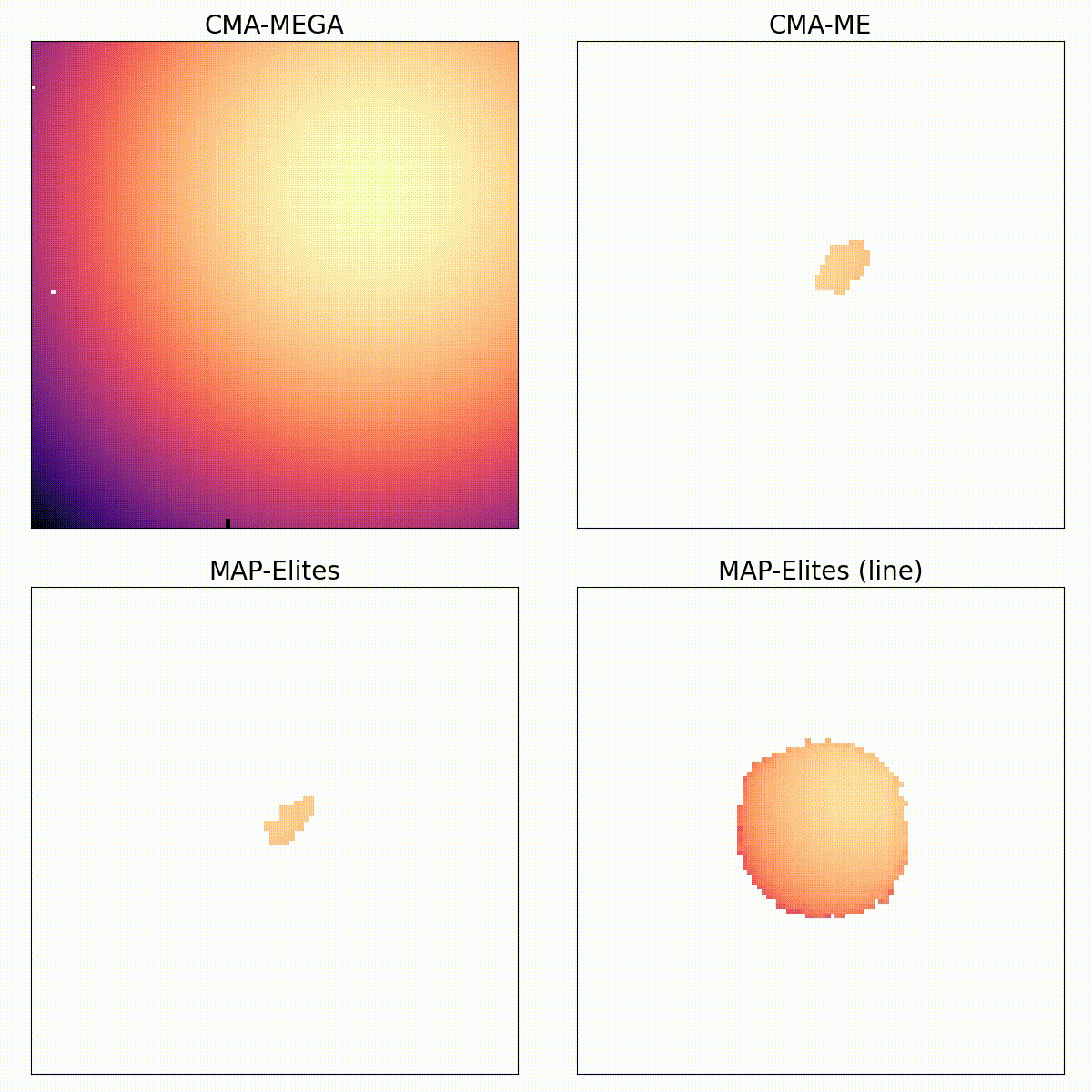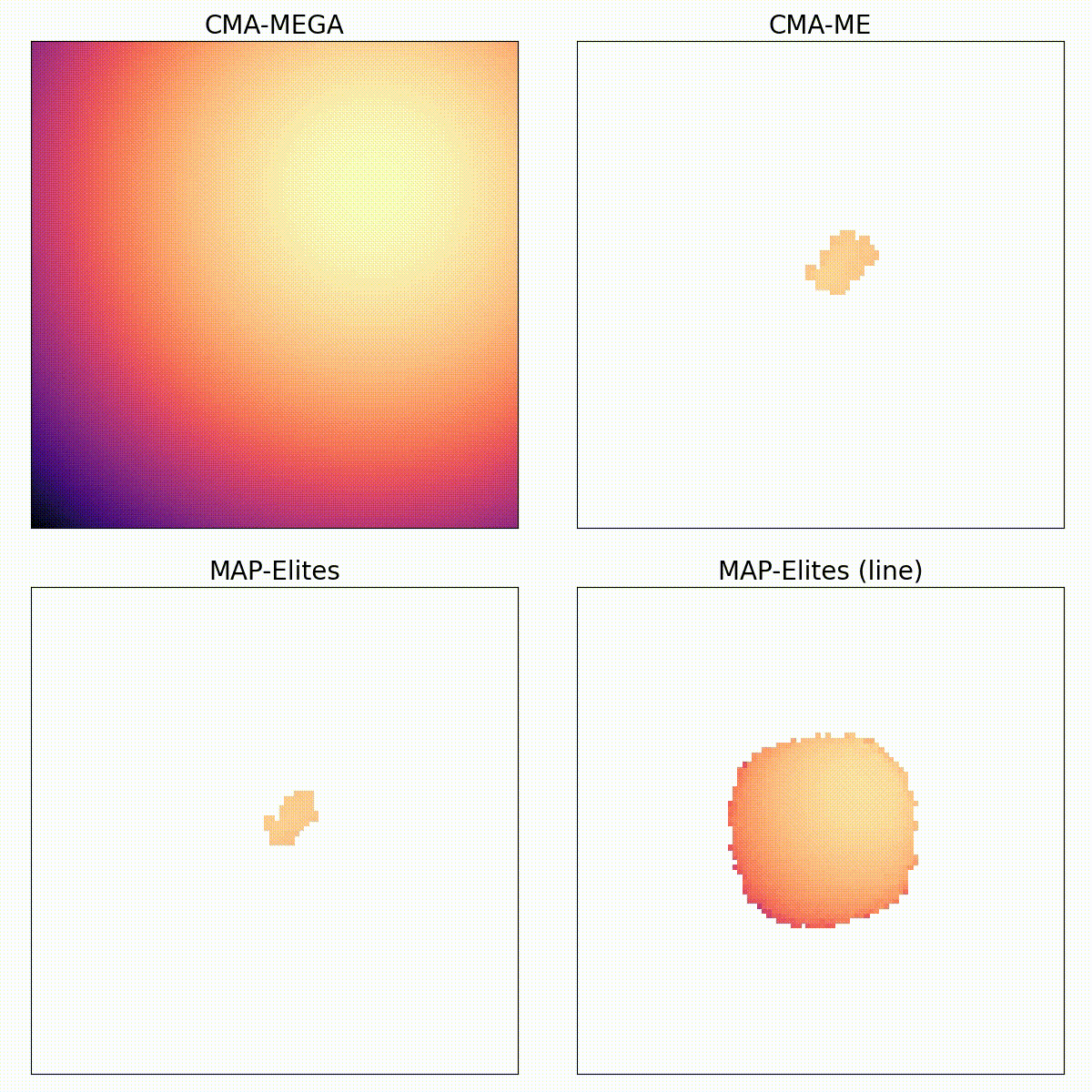
Training Diverse High-Dimensional Controllers by Scaling Covariance Matrix Adaptation MAP-Annealing
B. Tjanaka, M. C. Fontaine, D. H. Lee, A. Kalkar, S. Nikolaidis
Robotics and Automation Letters (RA-L), 2023
Abstract
Pre-training a diverse set of neural network controllers in simulation has enabled robots to adapt online to damage in robot locomotion tasks. However, finding diverse, high-performing controllers requires expensive network training and extensive tuning of a large number of hyperparameters. On the other hand, Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), an evolution strategies (ES)-based quality diversity algorithm, does not have these limitations and has achieved state-of-the-art performance on standard QD benchmarks. However, CMA-MAE cannot scale to modern neural network controllers due to its quadratic complexity. We leverage efficient approximation methods in ES to propose three new CMA-MAE variants that scale to high dimensions. Our experiments show that the variants outperform ES-based baselines in benchmark robotic locomotion tasks, while being comparable with or exceeding state-of-the-art deep reinforcement learning-based quality diversity algorithms.
Covariance matrix adaptation map-annealing
M. C. Fontaine and S. Nikolaidis
Genetic and Evolutionary Computation Conference (GECCO), July 2023
Best Evolutionary Machine Learning Paper Award
Abstract
Single-objective optimization algorithms search for the single highest-quality solution with respect to an objective. Quality diversity (QD) optimization algorithms, such as Covariance Matrix Adaptation MAP-Elites (CMA-ME), search for a collection of solutions that are both high-quality with respect to an objective and diverse with respect to specified measure functions. However, CMA-ME suffers from three major limitations highlighted by the QD community: prematurely abandoning the objective in favor of exploration, struggling to explore flat objectives, and having poor performance for low-resolution archives. We propose a new quality diversity algorithm, Covariance Matrix Adaptation MAP-Annealing (CMA-MAE), that addresses all three limitations. We provide theoretical justifications for the new algorithm with respect to each limitation. Our theory informs our experiments, which support the theory and show that CMA-MAE achieves state-of-the-art performance and robustness.
pyribs: A Bare-Bones Python Library for Quality Diversity Optimization
B. Tjanaka, M. C. Fontaine, D. H. Lee, Y. Zhang, N. R. Balam, N. Dennler, S. S. Garlanka, N. D. Klapsis, S. Nikolaidis
Genetic and Evolutionary Computation Conference (GECCO), July 2023
Abstract
Recent years have seen a rise in the popularity of quality diversity (QD) optimization, a branch of optimization that seeks to find a collection of diverse, high-performing solutions to a given problem. To grow further, we believe the QD community faces two challenges: developing a framework to represent the field's growing array of algorithms, and implementing that framework in software that supports a range of researchers and practitioners. To address these challenges, we have developed pyribs, a library built on a highly modular conceptual QD framework. By replacing components in the conceptual framework, and hence in pyribs, users can compose algorithms from across the QD literature; equally important, they can identify unexplored algorithm variations. Furthermore, pyribs makes this framework simple, flexible, and accessible, with a user-friendly API supported by extensive documentation and tutorials. This paper overviews the creation of pyribs, focusing on the conceptual framework that it implements and the design principles that have guided the library's development.
Approximating Gradients for Differentiable Quality Diversity in Reinforcement Learning
B. Tjanaka, M. C. Fontaine, J. Togelius, S. Nikolaidis
Genetic and Evolutionary Computation Conference, 2022
Abstract
Consider a walking agent that must adapt to damage. To approach this task, we can train a collection of policies and have the agent select a suitable policy when damaged. Training this collection may be viewed as a quality diversity (QD) optimization problem, where we search for solutions (policies) which maximize an objective (walking forward) while spanning a set of measures (measurable characteristics). Recent work shows that differentiable quality diversity (DQD) algorithms greatly accelerate QD optimization when exact gradients are available for the objective and measures. However, such gradients are typically unavailable in RL settings due to non-differentiable environments. To apply DQD in RL settings, we propose to approximate objective and measure gradients with evolution strategies and actor-critic methods. We develop two variants of the DQD algorithm CMA-MEGA, each with different gradient approximations, and evaluate them on four simulated walking tasks. One variant achieves comparable performance (QD score) with the state-of-the-art PGA-MAP-Elites in two tasks. The other variant performs comparably in all tasks but is less efficient than PGA-MAP-Elites in two tasks. These results provide insight into the limitations of CMA-MEGA in domains that require rigorous optimization of the objective and where exact gradients are unavailable.
Differentiable Quality Diversity
M. C. Fontaine, S. Nikolaidis
Advances in Neural Information Processing Systems, 2021
NeurIPS 2021 Oral
Abstract
Quality diversity (QD) is a growing branch of stochastic optimization research that studies the problem of generating an archive of solutions that maximize a given objective function but are also diverse with respect to a set of specified measure functions. However, even when these functions are differentiable, QD algorithms treat them as "black boxes", ignoring gradient information. We present the differentiable quality diversity (DQD) problem, a special case of QD, where both the objective and measure functions are first order differentiable. We then present MAP-Elites via Gradient Arborescence (MEGA), a DQD algorithm that leverages gradient information to efficiently explore the joint range of the objective and measure functions. Results in two QD benchmark domains and in searching the latent space of a StyleGAN show that MEGA significantly outperforms state-of-the-art QD algorithms, highlighting DQD's promise for efficient quality diversity optimization when gradient information is available.
Covariance Matrix Adaptation for the Rapid Illumination of Behavior Space
M. C. Fontaine, J. Togelius, S. Nikolaidis, A. Hoover
2020 Genetic and Evolutionary Computation Conference, June 2020
Abstract
We focus on the challenge of finding a diverse collection of quality solutions on complex continuous domains. While quality diversity (QD) algorithms like Novelty Search with Local Competition (NSLC) and MAP-Elites are designed to generate a diverse range of solutions, these algorithms require a large number of evaluations for exploration of continuous spaces. Meanwhile, variants of the Covariance Matrix Adaptation Evolution Strategy (CMA-ES) are among the best-performing derivative-free optimizers in single-objective continuous domains. This paper proposes a new QD algorithm called Covariance Matrix Adaptation MAP-Elites (CMA-ME). Our new algorithm combines the self-adaptation techniques of CMA-ES with archiving and mapping techniques for maintaining diversity in QD. Results from experiments based on standard continuous optimization benchmarks show that CMA-ME finds better-quality solutions than MAP-Elites; similarly, results on the strategic game Hearthstone show that CMA-ME finds both a higher overall quality and broader diversity of strategies than both CMA-ES and MAP-Elites. Overall, CMA-ME more than doubles the performance of MAP-Elites using standard QD performance metrics. These results suggest that QD algorithms augmented by operators from state-of-the-art optimization algorithms can yield high-performing methods for simultaneously exploring and optimizing continuous search spaces, with significant applications to design, testing, and reinforcement learning among other domains.